
Support Vector Machine (SVM)
SVM is a supervised machine learning algorithm that is used for both classification and regression problems.
SVM is used for both linear separable data and non-linear separable data.
For non-linear data, kernel functions are used.
Let’s learn about SVC (Support vector classifier) in linear separable data which is used for classification problems in this article.
Topics covered in this story.
- Linear separable data
- SVM in linear separable data
- What is a hyperplane?
- What does SVM do?
- Important terms used in SVM
- Why it is named as support vector machines?
- Math behind SVM
- How to find the best hyperplane?
- How do we maximize the margin?
Linear separable data
1. One-dimensional space

Suppose we have two classes red and green, and if we are able to find a boundary that splits the two class means, it is said to be linearly separable data.

Here, we could come up with one point that acts as a boundary between two classes. The data points below the particular point belong to the red class and above that particular point belong to the green class.
Here the data points are linearly separable in this dimension.
2. Two-dimensional space

Likewise, in two-dimensional space, we can come up with a line that acts as a boundary between two classes.
Here, the data points are linearly separable in this dimension.
SVM in linear separable data
SVM classifies two classes using a hyperplane. Hyperplanes are decision boundaries that classify data
What is Hyperplane?
A hyperplane is an n-1 dimensional subspace in an n-dimensional space.
- SVC is a single point in a one-dimensional space
- SVC is a one-dimensional line in a two-dimensional space.
- SVC is a two dimensional plane in a three-dimensional space.
- When the data-points are in more than three dimensions, SVC is a hyperplane.
What does SVM do?
SVM algorithm finds the best hyperplane that goes in the middle of the two classes with a maximum margin on both sides.

Important terms used in SVM
- Support vectors
- Margin
- Hard Margin
- Soft Margin
Support Vectors
The data points closest to the hyperplane in both the classes are known as support vectors.
If a data point which is a support vector is removed, then the position of the hyperplane is changed.
If a data point that is not a support vector is removed, it has no effect on the model.
Margin
The distance between the hyperplane and support vectors is known as margin.
Hard Margin
Hard Margin means none of the data points from both the classes falls within the margin.
Soft Margin
If data points are not linearly separable means, some data points are allowed inside the margin. This is known as the soft margin.
Why it is named as support vector machines?
The hyperplane is determined by the support vectors. If we remove data points other than support vectors, the hyperplane doesn’t change. If a data point which is a support vector is removed, then the position of the hyperplane is changed.
Now let’s come to the important points.
- How to find the best hyperplane?
- How do we maximize the margin?
First, let’s understand the math behind SVM, and then we will come to the above 2 questions.
Math behind SVM
The basic principle behind SVM is we want to draw a hyperplane with a maximum margin that separated two classes. Suppose we want to separate two classes C1 and C2 by using SVC in two-dimensional space. Then we want to predict the class of unknown feature vector X as either Class C1 or Class C2.
We can use a linear equation
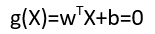
w → indicates weight vector which is perpendicular to the hyperplane. It represents the orientation of hyperplane in d-dimensional space where d is the dimensionality of the feature vector.
b → It represents the position of the hyperplane in d-dimensional space.
This linear equation in two dimensions represents a straight line. It represents a plane in three-dimensional space and a hyperplane in more than 3 dimensions.
Coming to the classification problem,
For every feature vector, we have to calculate the linear function in such a way that
- If the feature vector lies on the positive side of the hyperplane,
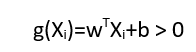
2. If the feature vector lies on the negative side of the hyperplane,
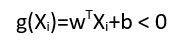
Classification rule is



Example:
Let’s take some data points and draw the hyperplane and calculate the value of wx+b for all data points.
Let’s calculate the linear function

For the given hyperplane, W=-1 and b= 5
Slope = Change in Y / Change in X
Take two data points on the hyperplane (straight line) and find the slope
Two data points → (2,3),(1,4)
Slope=(y1-y2)/x1-x2)
Slope=3–4 / 2–1 = -1
b= 5 [The value of y when x=0]

- The point lies on the hyperplane
(1,4) → The feature vector lies on the hyperplane.
g(X)=wX +b
g(X)=(-1)(1,4)+5 => (-1)(1)+(-1)(4)+5
g(X)= -1–4+5=0
g(X)=0
2. Support vector belongs to + label
(2,2) → support vector belongs to + label
g(X)=(-1)(2,2)+5=>(-1)(2)+(-1)(2)+5
g(X)=-2–2+5=1
g(X)=1
3. Support vector belongs to -label
(3,3) → support vector belongs to -label
g(x)=(-1)(3,3)+5 =(-1)(3)+(-1)(3)+5
g(x)=-3–3+5=-1
g(x)=-1
4. Data point belongs to negative side of hyperplane
(3,4) → feature vector belongs to negative side of hyperplane
g(x)=(-1)(3,4)=(-1)(3)+(-1)(4)+5
g(x)=-3–4+5=-2
g(x)=-2 which satisfies the condition g(x)<-1
5. Data point belongs to the positive side of the hyperplane.
(1,2) → Feature vector belongs to the positive side of the hyperplane
g(x)=(-1)(1,2)+5 =(-1)(1)+(-1)(2)+5
g(x)=-1–2+5=3
g(x)=3 which satisfies the condition g(x)>1
How to predict the value of unknown feature vector?
During the training phase SVM finds the best hyperplane and calculates w and b for that hyperplane. If we want to find the class of unknown feature vector, SVM predicts by applying the value of that vector in the equation.
If the value is negative, it belongs to Class C2 [Negative label] or if the value is positive, it belongs to Class C1[positive label]
How to find the best hyperplane?
During the training phase, it will start with some random hyperplane and check whether there is an error. If a data point that belongs to class C1 is predicted as class C2 means then it will change the value of m and rotate the hyperplane in such a way that the error data point goes back to the correct side. In the training phase, the model will find the correct m and b that gives zero training error.
Let’s understand how it rotates the hyperplane by using vector calculus.
In the random hyperplane drawn, we get one error point. Let’s draw a slope vector m ⃗ which is perpendicular to the hyperplane. From the origin of the slope vector draw a vector to the error point v ⃗

Here, we have to move the error point below the hyperplane. To push the datapoint below the line, we have to increase the angle between the slope vector and the data vector.
If we subtract both vectors, the angle between them will be increased.
First, we have to flip the direction of the data vector, so we will get -v ⃗
Now add this vector and slope vector.

The resultant vector will be the new slope vector. Then draw a hyperplane perpendicular to that new slope vector. The line has been rotated by the slope vector. Now the error point goes below the new hyperplane.

Similarly, SVM will calculate the new slope for all error points and find the hyperplane which splits both classes.
How do we maximize the margin?
After finding all possible hyperplane which separates the two classes, we will calculate w and d for each hyperplane. w indicates the slope vector of the hyperplane.
d represents the distance of the closest data point from the hyperplane.
After sorting the d value, we will choose the hyperplane which has the maximum distance from the closest data point from both classes.
Implementation of SVM algorithm on Iris dataset.
GitHub link → The code can be downloaded as a jupyter notebook from my Github.
Conclusion
SVM is used for both classification and regression problems. In this article, we have learned how SVM deals with classification problems for linearly separable data. SVM also supports non-linearly separable data.
My other blogs on Machine learning
Understanding Decision Trees in Machine Learning
An Introduction to K-Nearest Neighbors Algorithm
Naive Bayes Classifier in Machine Learning
I hope that you have found this article helpful. Thanks for reading!
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
