
KNN
The K-Nearest Neighbours (KNN) algorithm is one of the simplest supervised machine learning algorithms that is used to solve both classification and regression problems.
KNN is also known as an instance-based model or a lazy learner because it doesn’t construct an internal model.
For classification problems, it will find the k nearest neighbors and predict the class by the majority vote of the nearest neighbors.
For regression problems, it will find the k nearest neighbors and predict the value by calculating the mean value of the nearest neighbors.
The main concept behind KNN is
Birds of same feather flock together
Topics covered in this story
- KNN Classification
- How to find the optimum k value?
- How to find the k nearest neighbors?
- Euclidean distance
- Why KNN is known as an instance-based method or Lazy learner
- Example dataset, dataset representation
- Calculating Euclidean distance
- Finding nearest neighbors
- Python Implementation of KNN Using sklearn
- How to find the best k value? Plot error vs k values.
KNN Classification
Let’s learn how to classify data using the knn algorithm. Suppose we have two classes circle and triangle.
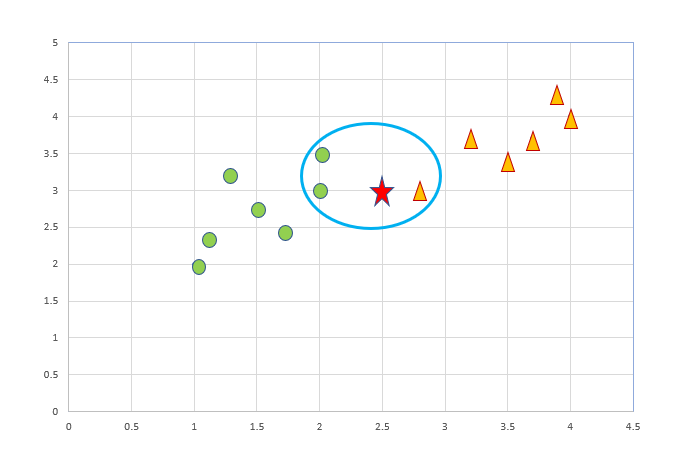
Below is the representation of data points in the feature space.

Now we have to predict the class of new query point (star shape shown in the figure). We have to predict whether the new data point (star shape) belongs to class circle or traingle.

First, we have to determine k value. k denotes the number of neighbors.
Second, we have to determine the nearest k neighbors based on distance.
This algorithm finds the k nearest neighbor, and classification is done based on the majority class of the k nearest neighbors.
Here in this example, I have shown the nearest neighbors inside the blue oval shape. So the majority class belongs to “Circle”, so the query point belongs to class circle.
Now, comes the important point.
1. How to find the optimum k value?
2. How to find the k nearest neighbors?
How to find the optimum k value?
Choosing the k value plays a significant role in determining the efficacy of the model.
- If we choose k =1 means the algorithm will be sensitive to outliers.
- If we choose k= all (means the total number of data points in the training set), the majority class in the training set will always win. Since knn classifies class based on majority voting mechanism. So all the test records will get the same class which is the majority class in the training set.
- Generally, k gets decided based on the square root of the number of data points.
- Always use k as an odd number. Since KNN predicts the class based on the majority voting mechanism, the chances of getting into a tie situation will be minimized.
- We can also use an error plot or accuracy plot to find the most favorable K value. Plot possible k values against error and find the k with minimum error and that k value is chosen as the favorable k value.
How to find the k nearest neighbors?
There are different techniques to find the k nearest neighbors.
- Euclidean distance
- Manhattan distance
- Minkowski distance
One of the most used techniques is the euclidean distance.
Euclidean distance
Euclidean distance is used to calculate the distance between two points in a plane or a three-dimensional space. Euclidean distance is based on the Pythagoras theorem.
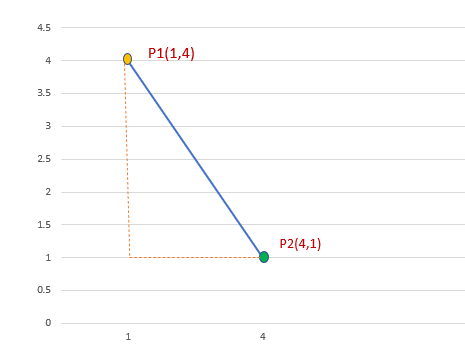
Let’s calculate the distance between P1 and P2
P1(1,4) and P2(4,1)
Pythagoras theorem
In any right-angled triangle, the square of the hypotenuse(longest side of a triangle) is equal to the sum of the other two sides of the triangle.

a² + b² = c²
→ c² = a² + b²
→ c= sqrt(a²+b²)
The Euclidean distance formula is derived from Pythagoras theorem

Now we can calculate the distance between two points P1(1,4) and P2(4,1) using the Euclidean distance formula

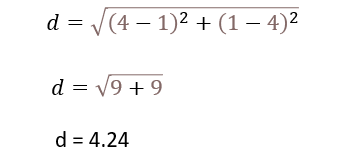
- KNN algorithm calculates the distance of all data points from the query points using techniques like euclidean distance.
- Then, it will select the k nearest neighbors.
- Then based on the majority voting mechanism, knn algorithm will predict the class of the query point.
Important point to remember:
The distance formula is highly dependent on how dimensions are measured. To ensure all dimensions have a similar scale, we normalize the data on all dimensions.
Why KNN is known as an instance-based method or Lazy learner
KNN algorithm is known as an instance-based method or lazy learner because it doesn’t explicitly learn a model. It doesn’t learn a discriminative function from the training data. It just memorizes the training instances which are used as “knowledge” for the prediction phase.
Example Dataset
I have taken a small data set that contains the features Height and Weight and the target variable BMI.

Let’s predict what is the BMI of a person for a particular height and weight?
Dataset Representation

Query Point

Predict the BMI of a person whose Height=150 cm, Weight= 61 kg.
This is our query point. Let’s predict whether it belongs to “Overweight”, "Normal” or “Underweight” category.
Let’s calculate euclidean distance and find out the nearest neighbors.
Calculating Euclidean distance
Calculate distance between data points and the query point using the euclidean distance formula. After calculating the distance for all data points, sort it and find the k nearest neighbors which are having the shortest distance.

Nearest neighbors

We have taken k=3
Out of 3 nearest neighbors, all 3 of them belong to the “Overweight” category So, the person whose height=150 cm and weight= 61 kg belongs to the “Overweight” category.
If two of them belong to the “Overweight” and one belongs to the “Normal” category means the majority wins.
Python Implementation of KNN Using sklearn
- Import the libraries.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
2. Load the data.
df=pd.read_csv("bmi.csv")
df.head(3)

3. Converting object to category
df.dtypes

df['BMI'] = df.BMI.astype('category')
df.dtypes

4. Split x and y variables.
x=df.iloc[:,0:2] x.head(3)
y=df.iloc[:,2] y.head(3)

5. Splitting dataset into training and test set
# Splitting the dataset into training and test set. from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.3, random_state=0)
6.KNN algorithm
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors= 3,weights = 'distance' ,metric="euclidean") knn.fit(x_train, y_train)
Output: KNeighborsClassifier(metric=’euclidean’, n_neighbors=3, weights=’distance’)
7.Accuracy score
from sklearn.metrics import accuracy_score
print("Accuracy of test set=",accuracy_score(y_test, y_pred)*100)
Output: Accuracy of test set= 100.0
8. Prediction
knn.predict([[150,61]])
Output: array([‘Overweight’], dtype=object)
So, knn algorithm predicted person whose height=150cm and weight=161 kg as “Overweight”
Some more predictions
knn.predict([[155,50]])
Output: array([‘Normal’], dtype=object)
knn.predict([[145,25]])
Output:array([‘Underweight’], dtype=object)
How to find the best k value?
Step 1: Possible k values
possible_k=[1,3,5,7,9,11]
Step 2: Finding Accuracy Score and MSE for each k value
Calculating Accuracy score for each k value and appending to list “ac_scores”
ac_scores=[]
for k in possible_k:
knn=KNeighborsClassifier(n_neighbors= k,weights = 'distance',metric="euclidean" )
knn.fit(x_train,y_train)
y_pred=knn.predict(x_test)
scores=accuracy_score(y_test,y_pred)
ac_scores.append(scores)
print ("Accuracy Scores :",ac_scores)
Output:
Accuracy Scores : [0.8333333333333334, 1.0, 1.0, 0.8333333333333334, 0.8333333333333334, 0.8333333333333334]
Step 3: Calculate Error
Error is calculated by subtracting the accuracy score from 1.
MSE=[1-x for x in ac_scores]
print ("MSE : ",MSE)
Output:
MSE : [0.16666666666666663, 0.0, 0.0, 0.16666666666666663, 0.16666666666666663, 0.16666666666666663]
Step 4: Find the best k value
Now, have to identify which k value has the minimum error.
Finding the index of MSE in the list MSE , which has the minimum value.
Then, find the k value of that particular index in the list possible_k.
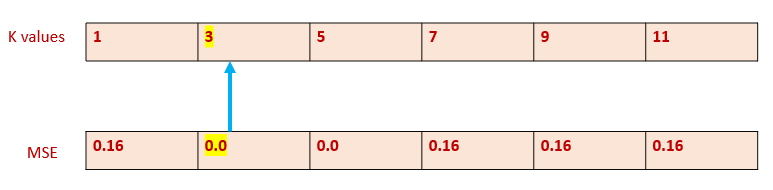
i=MSE.index(min(MSE))
best_k=possible_k[i]
print ("Best value of k is ",best_k)
Output: The best value of k is 3
Step 5: Plotting MSE vs k
plt.plot(possible_k,MSE)
plt.xlabel("Number of Neighbors k")
plt.ylabel("MSE")
plt.show()
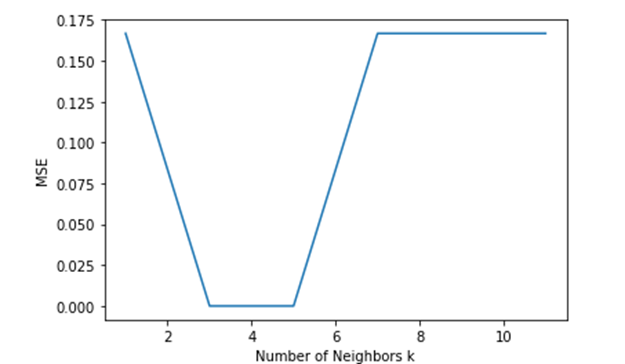
We can interpret from the graph that error is less for k=3 and k=5.
Conclusion
KNN is easy to implement since it requires only two parameters [k and distance function].KNN is also used for regression problems. In regression, it predicts the value based on the average value of the nearest neighbors rather than the majority voting mechanism.
My other blogs on Machine learning
Understanding Decision Trees in Machine Learning
Naive Bayes Classifier in Machine Learning
An Introduction to Support Vector Machine
I hope that you have found this article helpful. Thanks for reading!
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
