Bias vs Variance, Overfitting vs Underfitting

Why we need a bias-variance tradeoff
In machine learning, we collect data and build models using training data. We apply that model to test data, which the model has not seen, and do predictions. Our main aim is to reduce the prediction error.
We build the model by minimizing training error but we are more concerned about test error/prediction error. Prediction error depends on bias and variance.
Bias- variance trade-off is needed for the following scenarios.
- To overcome underfitting and overfitting condition
- To have consistencies in predictions.
Let’s learn about the concepts behind the bias-variance trade-off in detail in this article.
Model Building
Before going into the bias-variance trade-off, let’s see how the training error and prediction error differ when we increase the model complexity.
Suppose, we have our data points look like this. We have to find the relationship between X and Y.
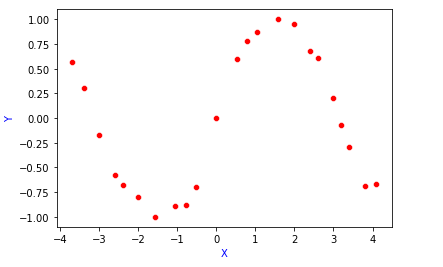
True relationship or True function between X and Y is denoted as f(X). This function is unknown.
Y=f(X)+ε
Now, we have to build a model which depicts the relationship between X and Y.
Input → Model → Output
Learning Algorithm: The learning algorithm will accept input and returns a function that depicts the relationship between X and Y.
Input → Learning Algorithm → f̂(X)
Example: In Linear Regression, the learning algorithm is gradient descent, which finds the best fit line based on cost function OLS(Least squares).
Suppose given a data set, we split it into training data and test data.
Training data — Build the model using training data
Test data — Predicting the output using the model chosen.
Now, let’s consider 4 models build on the training data.
In all the models, we are making an assumption of how y is related to x.
- Simple Model → Degree 1 → y=f̂(x) = w0 +w1x

Here in this simple model, the fitted line is far away from the data points, so the fitting error/training error will be high.
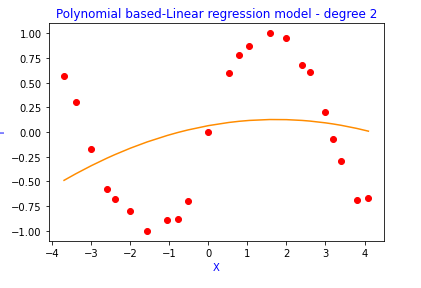
2. Degree 2 polynomial
y=f̂(x) = w0 +w1x + w2x²
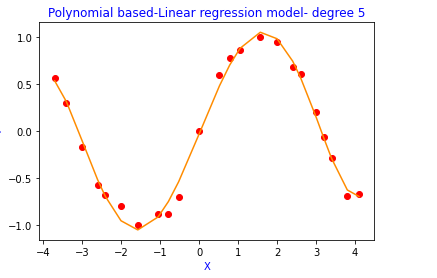
3. Degree 5 polynomial
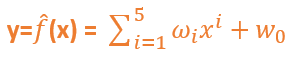
4. Complex Model → Degree 20


Here, in this complex model, the fitted curve passes through all the data points, so the fitting error/training error will be close to zero. This model tries to memorize the data along with the noise instead of generalizing it. So, this model won’t perform well on test data/validation data which is unseen. This scenario is known as Overfitting.
Now if we do prediction using these 4 models on validation data, we will get different prediction errors.
Now plotting training error and prediction error vs model complexity( in our case, degree of polynomial)
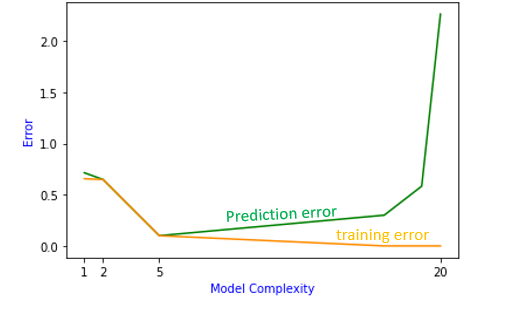
From the above graph, we could see that as model complexity increases[degree 1, degree2, degree 5, degree 20], training error tends to decrease.
But prediction error decreases to some extent and when the model becomes more complex, it increases.
There is a trade-off between training error and prediction error. At the end of the two curves, there is a high bias at one end and high variance at another end. So, there is a trade-off between bias and variance to achieve the ideal model complexity.

What is Bias-Variance Trade-off?
Bias
Let’s say f(x) is the true model and f̂(x) is the estimate of the model, then
Bias(f̂(x) )= E[f̂(x)]-f(x)
Bias tells us the difference between the expected value and the true function.
E[f̂(x)] → Expected value of the model.
How to calculate the expected value of the model.
We build the model (f̂(x)) using the same form( ex. polynomial degree 1) on different random samples drawn from the training data. Then we will calculate the expected value of all the functions which is denoted as E[f̂(x)].

In the above plot, the orange fitted curve is the average of all the complex models (degree=20) performed on different random samples drawn from the training data.
In the above plot, the green fitted line is the average of all the simple models(degree=1) performed on different random samples drawn from the training data.
From the above plot, we can see that simple model have a high bias. Because the average function is far away from the true function.
Complex models have low bias. They fit the data perfectly.
Variance
Variance tells us how one f̂(x) differs from the expected value of the model E(f̂(x)).
Variance(f̂(x) )= E[(f̂(x)]-E[f̂(x)])²]
So, for complex models, variance tends to be higher because a small change in the training sample will lead to different f̂(x). Because complex models, memorize the data points.
For simple models, there won’t be much difference in f̂(x), if we change the training sample a little bit. Simple models generalize the pattern.
So, from bias and variance, we can say that,
Simple models may have high bias and low variance.
Complex models may have low bias and high variance
There is a trade-off between bias and variance because both contribute to error.
Expected Prediction Error
Expected Prediction Error depends on three errors
- Bias
- Variance
- Noise (Irreducible Error)
Expected Predicted Error Formula
EPE= Bias² + Variance + Irreducible Error
Using model f̂(x), we are predicting the value of a new data point (x,y) that is not in training data.
Then the expected mean square error will be
EPE =E[(y-f̂(x)²]
From the formula of EPE, we know that error depends on bias and variance.
So, from the above plot
- The prediction error is high when bias is high.
- The prediction error is high when variance is high.
- degree 1 polynomial → training error and the prediction error is high → Underfitting
- degree 2 polynomial → training error and prediction error high →Underfitting
- degree 5 polynomial → training error is less and the difference between training error and the prediction error is less. → Best fit
- degree 20 polynomial → training error is less and prediction error is very high →Overfitting
Key Takeaways
- Simple models may have high bias and low variance.
- Simple models will be more generic and sometimes will tend to underfit.
- Complex models may have high variance and low bias.
- Complex models will memorize the data and will tend to overfit.
- Best fit models will have low bias and low variance.
Thanks for reading and I hope you all like it.
If you like to read more of my tutorials, follow me on Medium, LinkedIn, Twitter.
Become a Medium Member by Clicking here: https://indhumathychelliah.medium.com/membership
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
