Sigmoid function, Log Loss, Odds Ratio, Model coefficient, Metrics

Logistic Regression
Logistic Regression is one of the supervised machine learning algorithms used for classification. In logistic regression, the dependent variable is categorical.
The objective of the model is, given the independent variables, what is the class likely to be? [For binary classification, 0 or 1]
In this article, I have covered the following concepts.
- How logistic regression uses the sigmoid function to predict the class?
- Which cost function is used to determine the best fit sigmoid curve?
- What are odds, odds ratio, log odds?
- How to interpret the model coefficient?
- How to get the odds ratio from the model coefficient?
- What are the metrics used for evaluating the model?
- How to set threshold value using ROC curve.
Why not Linear Regression?
In Logistic Regression-binary classification, we will predict the output as 0 or 1.
Example:
- Diabetic (1) or not (0)
- Spam (1) or Ham (0)
- Malignant(1) or not (0)
In Linear Regression, output prediction will be continuous. So, if we fit a linear model, it won’t predict the output between 0 and 1.
So, we have to transform the linear model to the S -curve using the sigmoid function, which will convert the input between 0 and 1.
Sigmoid Function
The sigmoid function is used to convert the input into range 0 and 1.
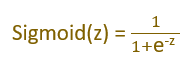
- If z → -∞, sigmoid(z) → 0
- If z → ∞ , sigmoid(z) → 1
- If z=0, sigmoid(z)=0.5

So, if we input the linear model to the sigmoid function, it will convert the input between range 0 and 1
In Linear regression, the predicted value of y is calculated by using the below equation.
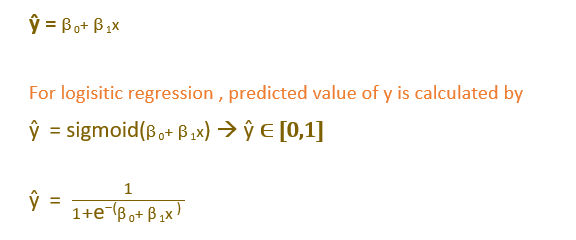
In logistic regression, ŷ is p(y=1|x). This means ŷ provides an estimate of the probability that y=1, given a particular set of values for independent variables(x)
→ If the predicted value is close to 1 means we can be more certain that the data point belongs to class 1.
→ If the predicted value is close to 0 means we can be more certain that the data point belongs to class 0.
How to determine the best fit sigmoid curve?
Cost Function
Why not least squares as cost function?
In logistic regression, the actual y value will be 0 or 1. The predicted y value ŷ will be between 0 and 1.
In the least-squares method, the error is calculated by subtracting actual y and predicted y value and squaring them
Error =(y-ŷ)²
If we calculate least squares for the misclassified data point say
y=0 and ŷ is close to 1, the error will be very less only.
The cost incurred is very less even for misclassified data points. This is one of the reasons, least squares is not used as a cost function for logistic regression.
Cost Function — Log loss (Binary Cross Entropy)
Log loss or Binary Cross Entropy is used as a cost function for logistic regression

Let’s check some properties of the classification cost function
- If y=ŷ, Error should be zero
- The error should be very high for misclassification
- The error should be greater than or equal to zero.
Let’s check whether these properties hold good for the log loss or binary cross-entropy function.
- If y=ŷ, the error should be zero.
Case 1: y=0 and ŷ=0 or close to 0

Case 2: y=1 and ŷ=1 or close to 1.

ln1 =0 and ln0 = -∞
2. The error should be very high for misclassification
Case 1: y=1 and ŷ=0 or close to 0
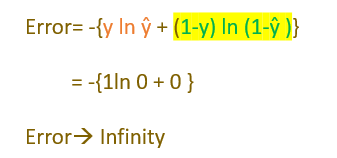
Case 2: y=0 and ŷ=1 or close to 1
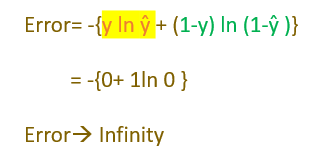
The error tends to be very high for misclassified data points.
3.The error should be greater than or equal to zero.
Error= -{y ln ŷ + (1-y) ln (1-ŷ)}
→ y is either o or 1
→ ŷ is always between 0 and 1
→ ln ŷ is negative and ln (1-ŷ) is negative
→ negative sign before the expression is included to make the error positive [ In linear regression least-squares method, we will be squaring the error]
So, the error will be always greater than or equal to zero.
Interpreting Model coefficient
To interpret the model coefficient, we need to know the terms odds, log odds, odds ratio.
Odds, Log Odds, Odds Ratio
Odds
Odds is defined as the probability of an event occurring divided by the probability of the event not occurring.
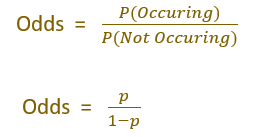
Example: Odds of getting 1 while rolling a fair die

Log odds (Logit Function)
Log odds =ln(p/1-p)
After applying the sigmoid function, we know that

From this equation, odds can be written as,
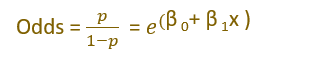
Log Odds = ln(p/1-p) = β 0+ β 1x
So, we can convert the logistic regression as a linear function by using log odds.
Odds Ratio
Odds Ratio is the ratio of two odds
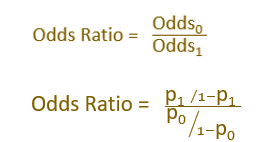
Interpreting Logistic Regression Coefficient
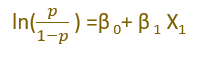
β 0 → Log odds is β 0 when X is zero.
β 1 → Change in log-odds associated with variable X1.
If X1 is numerical variables,β 1 indicates, for every one-unit increase in X1, log odds is increased by β 1.
If X1 is a binary categorical variable, β 1 indicates, change in log odds for x1=1 relative to X1=0.
How to get Odds Ratio from the model coefficient?
Odds Ratio in Logistic Regression
The odds ratio of an independent variable in logistic regression depends on how that odds change with one unit increase in that particular variable by keeping all the other independent variables constant.
β 1 → Change in log-odds associated with variable X1.
The odds Ratio for variable X1 is the exponential of β 1

Derivation of Odds Ratio from Model Coefficient

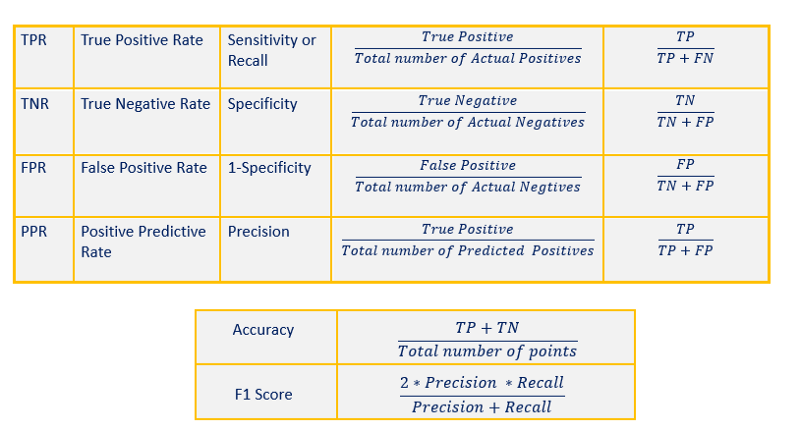
Evaluation Metrics for Classification
- Accuracy
- TPR
- TNR
- FPR
- PPR
- F1 Score
Accuracy
Accuracy measures the proportion of actual predictions out of total predictions. Here we didn’t know the exact distribution of error. [Distribution between False-positive and False negative]

In the accuracy metric, we didn’t know the exact distribution of error[Distribution between False-positive and False negative]. So, we go for other metrics.
Sensitivity or Recall or True Positive rate(TPR)
True Positive Rate measures the proportion of actual positives that are correctly classified.
Specificity or True Negative Rate (TNR)
True Negative Rate measure the proportion of actual negatives that are correctly classified.
False Positive rate or (1-Specificity)
False Positive Rate measure the proportion of actual negatives that are misclassified.
Positive Predicted Rate (PPR) or Precision
Positive Predicted Rate measures the proportion of the actual positives out of total positive predictions.
F1 Score
F1 Score is the harmonic mean of precision and recall
How to calculate the harmonic mean?
- Take the inverse of precision and recall (1/precision,1/recall)
- Find the average of inverse of precision and recall
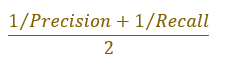
3. Then, inverse the result.

Which metric to chose?
It depends on the problem statement.
- Accuracy → When we need to know the prediction accuracy like how many 1’s classified as 1 and how many 0’s classified as 0 but not concerned with the distribution of errors(FP and FN).
- Sensitivity → When we want all our positive records to be identified correctly. More importance on False Negative[In cancer dataset, cancer patients should be predicted correctly]
- Specificity → When we don’t want any negative labels to be misclassified.More importance on False Positive[In spam detection, we want all our genuine emails to be predicted properly]
- F1 score metric is used for an imbalanced dataset.
Metrics Formula
What is the threshold level? How to set the threshold level?
Threshold Level
The logistic regression model predicts the outcome in terms of probability. But, we want to make a prediction of 0 or 1. This can be done by setting a threshold value.
If the threshold value is set as 0.5 means, the predicted probability greater than 0.5 will be converted to 1 and the remaining values as 0.
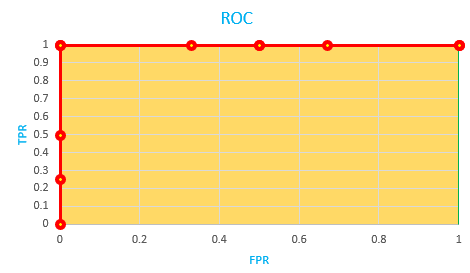
ROC Curve
ROC curve is the trade-off between FPR and TPR or (1-Specificity vs Sensitivity) at all classification threshold levels.
FPR → Fraction of negative labels misclassified.
TPR →Fraction of positive labels correctly classified
If FPR=TPR=0 means the model predicts all instances as the negative class.
If FPR=TPR=1 means model predicts all instances as the positive class
If TPR=1, FPR=0 means the model predicts all data points correctly. (ideal model)
Example: I have calculated all metrics from actual y and predicted probability at all threshold levels.

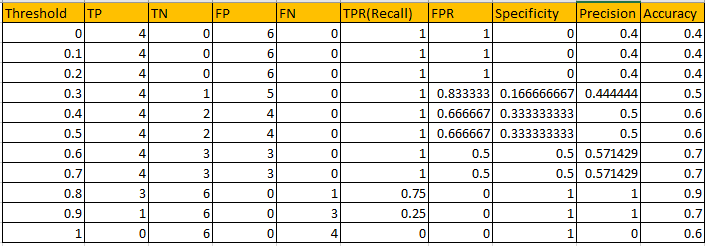
Let’s plot ROC-Curve [FPR vs TPR] at all threshold levels.
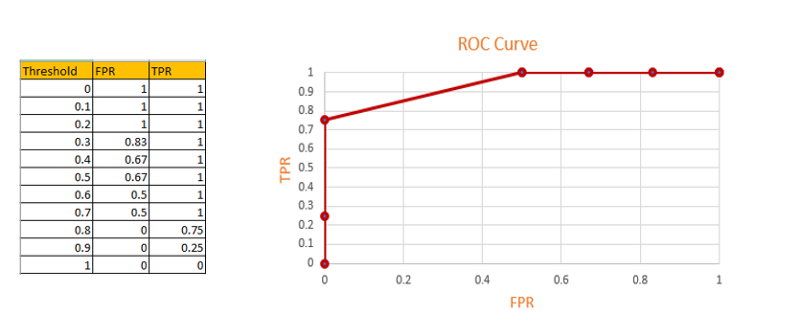
Interpretation of ROC curve
From the above ROC curve, we can choose the best threshold level. At FPR =0 and TPR =0.75, is the best threshold level for the above ROC curve.
AUC tends to be higher for that point and also FPR is zero.

AUC — Area under the curve is the area covered by the ROC curve. AUC range from 0–1.
For any random classifier, AUC =0.5. So AUC score for good models should be between 0.5 and 1.
If TPR=1, FPR=0 means the model predicts all data points correctly. (ideal model). In this case, AUC is 1.
Why ROC curve is used?
- To compare the performance of different models. AUC is calculated from the ROC curve and the model which has a higher AUC performs better.
- To select the best threshold for the model.
Key Takeaways
- To interpret the model coefficient we use the equation
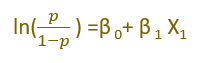
2. To calculate ŷ, we use the equation
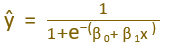
3. Exponential model coefficient gives the odds ratio

Conclusion
In this article, I have covered the basic concepts in Logistic Regression like how the model predicts the output, how to interpret the model coefficient, how to evaluate the performance of the model. I hope you all like it.
Thanks for reading!
Watch this space for more articles on Python and DataScience. If you like to read more of my tutorials, follow me on Medium, LinkedIn, Twitter.
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
