
Correlation Coefficient
In machine learning, before we generate any model, we need to understand the relationship between independent variables and the target variable.
The correlation coefficient is used as a measure of association. Let’s learn in detail about correlation and covariance in this article.
Topics covered in this story
- What is the correlation?
- Types of correlation.
- Pearson’s Correlation Coefficient
- What is covariance?
- Why correlation is preferred over covariance?
- What is the range of the correlation coefficient?
- Interpreting Pearson’s correlation coefficient.
- How to visualize the correlation?
- Calculating Covariance and Coefficient Correlation.
- Correlation vs Covariance
What is Correlation?
Correlation is a measure of association. Correlation is used for bivariate analysis. It is a measure of how well the two variables are related.
Types of correlation
- Positive Correlation
When the value of one variable increases, the other variable also increases.
2. Negative Correlation
When the value of one variable increases, the other variable decreases.
3. No Correlation
When there is no linear relationship between two variables.

Pearson’s Correlation Coefficient
The measure of correlation is known as the correlation coefficient.
Pearson’s Correlation Coefficient is a type of correlation coefficient that measures the linear association. It is denoted by r. The value of r ranges from -1 to +1.
Formula

Let’s understand covariance first.
What is covariance?
Covariance is also a measure of association. Covariance is a measure of the relationship between two random variables.
Formula

Covariance is also used to measure the strength and direction of the relationship between two random variables.
Example. Let’s see how to calculate the strength and direction of the relationship between two variables using covariance.
- First, let’s plot variable x vs variable y.
Then we have taken x̅ (Mean of x) and ȳ (Mean of y) - Splitting the scatter cloud into four quadrants using the mean of x and y.
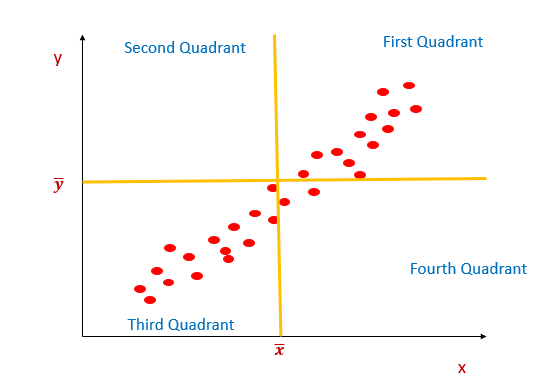
3. Now let’s take a data point in the first quadrant and calculate covariance for that data point.
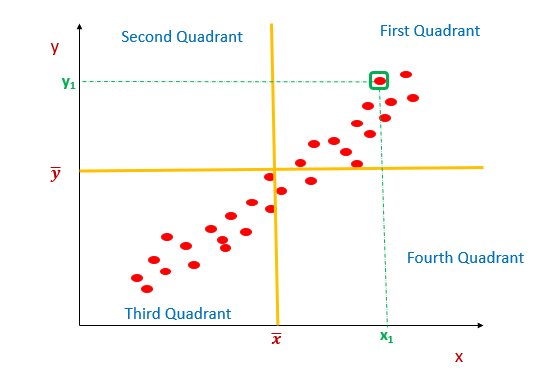
4. For the data point in the first quadrant, both x1 and y1 are greater than x̅ (Mean of x) and ȳ (Mean of y). This indicates (xi -x̅ )(yi-ȳ) should be positive.
Likewise, covariance is a positive number for all data points in the first quadrant.
5. Now let’s take a data point in the third quadrant and calculate covariance for that data point.

6. For the data point in the third quadrant, both x1and y1 are less than x̅ (Mean of x) and ȳ (Mean of y). This indicates (xi -x̅ )(yi-ȳ) should be positive.
Likewise, covariance is a positive number for all data points in the third quadrant.
7. The first quadrant and third quadrant contribute to a positive relationship.
8. Since in the above diagram, most of the data points belong to the first and third quadrant, covariance will be a positive number.
Inference
- Positive Covariance number indicates a positive relationship [ x increases, y also increases]
- Covariance number ranges from -∞ to +∞.
Negative relationship
If more data points fall in the second and fourth quadrant, covariance will be negative. It implies a negative relationship.
In the below-mentioned diagram, for the data point(x1,y1) in the second quadrant, x1 is less than x̅ (Mean of x), and y1 is greater than ȳ (Mean of y). This indicates (xi -x̅ )(yi-ȳ) will be negative.
For all data points in the second quadrant, covariance will be a negative number.

The second quadrant and fourth quadrant contribute to a negative relationship.
No relationship
If data points scatter in all quadrants, covariance will be close to 0. It implies no relationship.
Why correlation is preferred over covariance?
Covariance is a very good measure of association. So why we need to go for correlation?
Covariance depends on units of x and y. If we change the scale of x and y, then covariance will also be changed.
Covariance units =(units of x) *(unit of y)
- If we have x and y in cm and if we find covariance, then the units will be cm²
- Then if we change the scale to km and find the covariance, the units will be in km². The value of covariance also will differ.
- So, covariance depends on scale. It will be difficult to interpret covariance since it is scale-dependent.
To normalize this and to get rid of units, we use the correlation coefficient.
Correlation Coefficient = Cov(x,y) / std dev(x) std dev(y)
The Correlation Coefficient is calculated by dividing the Covariance of x,y by the Standard deviation of x and y.
Units of Cov(x,y) = (unit of x)*(unit of y)
Units of the standard deviation of x = unit of x
Units of the standard deviation of y = unit of y.
So, unit of correlation coefficient = (unit of x)*(unit of y) / (unit of x) (unit of y)
So, in the correlation coefficient formula, units get canceled. The correlation coefficient does not have any units. It’s just a number.
What is the range of the correlation coefficient?
The range of the correlation coefficient is -1 to +1.
Let’s understand the range of correlation coefficient.
- Variable x will be having the best correlation with itself. So, corr(x,x) will be the best or maximum correlation.
- Corr (x,x) = Cov(x,x)/(std dev (x) * std dev (x))
- Covariance (x,x) is equal to variance(x)
- Variance is a measure of spread. Variance is used to describe how far each data point deviates from the mean.

5. Standard deviation is calculated from the square root of variance. So,
std dev(x) * std dev(x) = var(x)
6. From step 3 and 5 ,
Corr(x,x) = Variance(x) /Variance(x) =1
So, the best or maximum correlation coefficient will be equal to 1.
7. Similarly, the worst or minimum correlation of a variable x will be with -x. So, corr(x, -x) will be equal to -1.
Corr(x,-x)= -Variance(x) /(Variance(x) = -1
So, the minimum correlation coefficient will be equal to -1.
Interpreting Pearson’s Correlation Coefficient
Now, we know that Pearson’s correlation coefficient ranges from -1 to +1.
- If Pearson’s correlation coefficient is close to 1 means, it has a strong positive correlation.
- If Pearson’s correlation coefficient is close to -1 means, it has a strong negative correlation.
- If Pearson’s correlation coefficient is close to 0 means, it has no linear correlation.
How to visualize the correlation?
A scatterplot is used to visualize the correlation between two numerical variables.
Example: I have taken a small data set (Height vs Weight). Let’s visualize the correlation between Height and Weight.
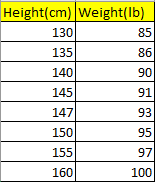
Scatter plot
sns.scatterplot(x=”Height(cm)”,y=”Weight(lb)”,data=df)

We can visualize the positive correlation between “Height” and “Weight” variables.
Heatmap.
sns.heatmap(df.corr(),annot=True,vmin=-1,vmax=1)
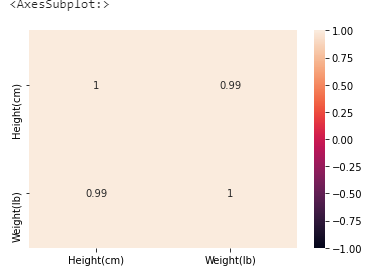
The correlation coefficient between Height vs Height and Weight vs Weight is 1.
The correlation coefficient between Height vs Weight is 0.99 (which is close to 1). So, it has a strong positive correlation.
Calculating covariance and correlation coefficient
Let’s calculate the covariance and correlation coefficient for the “Height-Weight” dataset.
Height in cm and Weight in lb.

Now, let’s convert weight (lbs) to weight (kgs) for the same dataset.

Now, once again we will calculate the covariance and correlation coefficient.

After converting weight in lbs to kgs, the covariance value is changed. But the correlation coefficient remains the same. It’s independent on the scale. It’s easy to interpret the correlation coefficient.
Correlation vs Covariance
- The value of the correlation coefficient ranges from -1 to +1. It is not affected by the scale of variables.
- The value of Covariance ranges from -∞ to + ∞. It is affected by the scale of variables.
Conclusion
In this article, we have learned about correlation coefficient and covariance. Both are used as a measure of association. But the correlation coefficient is preferred over covariance because it does not have any units. It’s scale-independent. If the correlation coefficient is close to 0 means, it doesn’t have any linear relationship. So, generating linear models for those cases makes no sense. Non-linear models may be better in such cases.
Happy Learning!!!
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
