Ensemble Technique- Bagging

Decision Trees
Decision trees are supervised machine learning algorithm that is used for both classification and regression tasks.
In this article, I have covered the following concepts.
- How to build a decision tree? What criteria are used to split the decision tree?
- How to overcome overfitting in the decision trees?
- What is bagging? How bagging decision trees work?
Decision Trees are a tree-like model that can be used to predict the class/value of a target variable. Decision trees handle non-linear data effectively.
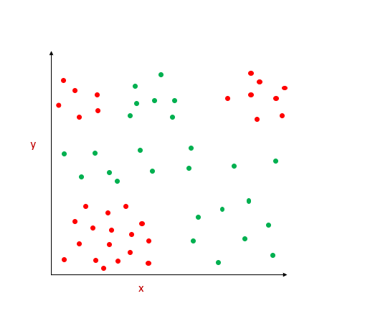
Suppose we have data points that are difficult to be linearly classified, the decision tree comes with an easy way to make the decision boundary.

It does by recursively partitioning the entire region. Let’s see how does the splitting is done.
Types of nodes
- Root Node — The topmost node in the decision tree is known as the root node.
- Internal Node — The subnodes which split further is known as an internal node.
- Leaf Node — The node that does not split further is known as leaf nodes
How to make the split in decision trees?
In the decision trees, at each node, the split is done based on the feature. If the feature is a continuous variable, the splitting condition is made on a certain threshold. [ex, age >50]. If the feature is a categorical variable, the splitting condition is made on all the values.[ex. Gender=Male].
The split which results in more reduction in impurity is selected.
The criteria used to calculate the best split are
- Classification Error
- Entropy
- Gini-index
Classification Error

How to calculate classification error?

Step 1: Calculate Classification Error at Node N1 [before split]
P[class 0] = 3/8
P[class 1]=5/8
1- max[p(c)]=1-[3/8,5/8] = 1–5/8= 3/8
classification error before split =3/8
Step 2: Calculate Classification Error at Node N2
P[class 0] = 1/4
P[class 1]=3/4
1- max[p(c)]=1-[1/4,3/4] = 1–3/4 = 1/4
Step 3. Calculate Classification Error at Node N3
P[class 0] = 2/4
P[class 1]=2/4
1- max[p(c)]=1-[2/4,2/4] = 1–2/4 = 2/8
Step 4. Average classification error of children node.
The proportion of data points in node n2 = 4/8
[ 4 out of 8 data points are in node n2]
The proportion of data points in node n3 = 4/8
[ 4 out of 8 data points are in node n3]
Weighted classification error = 4/8 * 1/4 + 4/8 * 2/4 = 3/8
classification error after split =3/8
5. Classification Error Change:
Classification error before split = 3/8
Classification error after split =3/8
Classification Error change = 3/8–3/8=0
Classification error for the above split is 0
Split is done based on each feature. For each feature, the change in classification error is calculated and the feature which gives the maximum classification error change is chosen for the split.
But sometimes, the classification error change will be zero. [In the above example, classification error change is zero]. So, this is not preferred much. Gini-index and entropy are preferred over classification error.
Entropy
Entropy is used to measure the homogeneity of a node in the decision tree. If the node is homogenous, entropy is 0. Entropy refers to impurity.
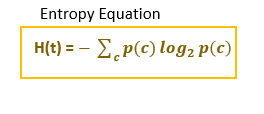
Entropy ranges from 0 to 1 [for 2-class problem]
- If the node is homogenous and all the data points belong to class 0 p[class=1]=0. Entropy will be 0.[Pure node- no impurity]
- If the node is homogenous and all the data points belong to class 1, p[class=1]=1. Entropy will be 0.[Pure node]
- If the node contains an equal number of data points belong to class 0 and class 1, then p[c=1]=0.5. Entropy will be 1.
Information Gain
Reduction in entropy (impurity) is known as Information Gain. If the information gain is more for a particular split, that split condition is executed first.
Information gain= Entropy before split — Entropy after split
Calculating entropy for the decision tree mentioned above.

Calculate Information Gain.

Split is done based on all features. For each feature, information gain is calculated and the feature which gives more information gain [more reduction in impurity] is chosen for the first split.
Gini-index
Gini-index is another measure of impurity.


Reduction in Gini-index

Gini impurity ranges from 0 to 0.5.
Entropy ranges from 0 to 1.
Problems in decision trees
Decision trees tend to overfit. It will keep on growing until all the leaf nodes are pure. All leaf nodes are homogenous[belongs to one class]. It will result in a tree that fits the training data accurately. So, it won’t generalize well and won’t perform well in test data.
How to overcome overfitting in decision trees?
To prevent overfitting, there should be some stopping criteria.
Two approaches to avoid overfitting.
- Truncation or Pre-pruning → There are many hyperparameters to truncate the trees. This is a top-down approach.
- Grow tree fully and then post prune. This is a bottom-up approach.
Pre-Pruning →Decision tree stopping criteria — Decision hyperparameters
- max_depth → The tree is allowed to grow up to this maximum depth mentioned.
- min_samples_split → the minimum number of samples required to split the decision node. [Decison nodes are nodes that have further splits]. If the decision node has fewer samples than mentioned in min_samples_split, it doesn’t split further.
- min_samples_leaf → the minimum number of samples required to be at a leaf node.
- max_features → the number of features to consider while making a split.
By tuning these parameters, it prevents trees from overfitting.
Post -Pruning → Reduced Error Pruning
This is a bottom-up approach. After a tree is fully grown, then post-prune the tree.
Training data is divided into a training set and validation set. The nodes are pruned iteratively and the performance of the pruned tree is checked in the validation set and training set. If the accuracy of pruned tree in the validation set is greater than the training set means, that node is pruned. Pruning means removing the subtree rooted in that node.
Why bagging is used?
Decision trees are high-variance models. It means a slight change in the training data, will lead to an entirely different model. Decision trees usually overfit. To overcome this situation, ensemble technique — bagging can be used.
What is bagging?
Bagging means Bootstrap Aggregation.
Bagging means building different models using sample subset and then aggregating the predictions of the different models to reduce variance.
How bagging reduces variance?
Suppose we have a set of ‘n’ independent observations say Z1, Z2….Zn. The variance of individual observation is σ2.
The mean of all data points will be (Z1+Z2+….+Zn)/n
Similarly, the variance of that mean will be σ2/n.
So, if we increase the number of data points, the variance of the mean is reduced. This is the concept behind bagging-decision trees.
Likewise, if we train multiple decision trees on a given data set and then aggregate the predictions. The variance will be reduced.
Bootstrapping samples
Bagging has two steps
- Bootstrapping
- Aggregation
Bootstrapping
We have understood that if we average the set of observations, the variance will be reduced. But we have only one training set and we have to build multiple decision trees.
Bootstrapping helps to create multiple subsets from the training data. Then we can build multiple trees on the bootstrapped samples.
Bootstrapping will randomly select repeated data points from the training set and create multiple subsets — sampling with replacement.
If we have ’n’ data points in the training set,
Probability of a particular data point to be selected in the bootstrap sample = 1/n
Probability of a particular data point not selected in the bootstrap sample =
1-1/n
So, the probability of each point not selected in the bootstrap sample =
(1–1/n)^n
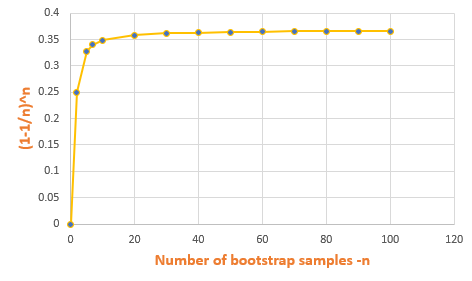
This method is also known as 0.632 bootstrap. It means the probability of each data point to be selected in the bootstrap sample =63.2%.
Each Bootstrap sample will contain 63.25% of the original training data. The remaining data points will be duplicates.
Each Bootstrap sample will not contain 36.8% of the training data. This is used as test data for the model built from that sample.
Aggregating the output
Now we have different bootstrap samples and have built ‘B’ decision trees for each ‘B’ bootstrap sample. The next step is aggregating the output.
Bagging classification trees
For each data point in the test set, the output class is predicted by ‘B’ trees. Based on the majority voting mechanism, the final class is calculated.
Another approach is to get the probability of the class from the ‘B’ trees, and the final class is classified from the average of the probability.
Bagging regression trees
For regression → For each data point in the test set, the target value is calculated from the average of all predictions from ‘B’ regression trees.
Bagging is bootstrap aggregating
Bagging on decision trees is done by creating bootstrap samples from the training data set and then built trees on bootstrap samples and then aggregating the output from all the trees and predicting the output.

How to calculate bagging error?
We know that in every bootstrap sample, approximately one-third of data points are left out(36.8%). Approximately only two-third of the original data points from the training set are included in the bootstrap samples(63.2%)
So for each tree built on the bootstrap samples, the error is calculated from the unused samples for that particular bootstrap sample. Measure the average of all the errors. This is known as Out Of BagError.
How to calculate feature importance?
Feature importance is calculated by using Gini-index/entropy.
While building trees for each bootstrap sample, a split in the node is done based on information gain. We will look at the information gain for that feature across all trees. Then average the information gain for that feature across all trees.
Advantages of bagging-decision trees
- The variance of the model is reduced.
- Multiple trees can be trained simultaneously.
Problem with bagging-decision trees.
If one feature is the strongest predictor and it has more impact on the target variable means, all the trees built on different bootstrap samples will have done split based on that strongest predictor first. So, all the trees trained on different bootstrap samples will be correlated. So, it won’t reduce the variance of the model.
To overcome this situation, random forests are used. In random forest also, we will train multiple trees. But both data points and features are randomly selected. By doing this, the trees are not correlated much which will improve the variance.
Conclusion
Decision trees use splitting criteria like Gini-index /entropy to split the node. Decision trees tend to overfit. To overcome overfitting, pre-pruning or post-pruning methods are used. Bagging decision trees are also used to prevent overfitting.
I hope that you have found this article helpful. Thanks for reading!
If you like to read more of my tutorials, follow me on medium, LinkedIn, Twitter.
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
